Específicos del lenguaje¶
En este bloque se tratan los casos de estudio relacionados con los aspectos específicos del lenguaje Python:
- Trucos
- Buenas prácticas
- Consejos
- Nuevas características introducidas por Python 3
LP-001 - Tareas no bloqueantes¶
Problema¶
Python es mucho más lento que otros frameworks o lenguajes, como nodejs, que usa conexiones no “bloqueantes” o “corrutinas”.
Nota
¿Qué es una corrutina (coroutine en inglés)?
Una corrutina es una compontente (función, clase o método) capaz de suspender su ejecución hasta recibir un cierto estímulo:
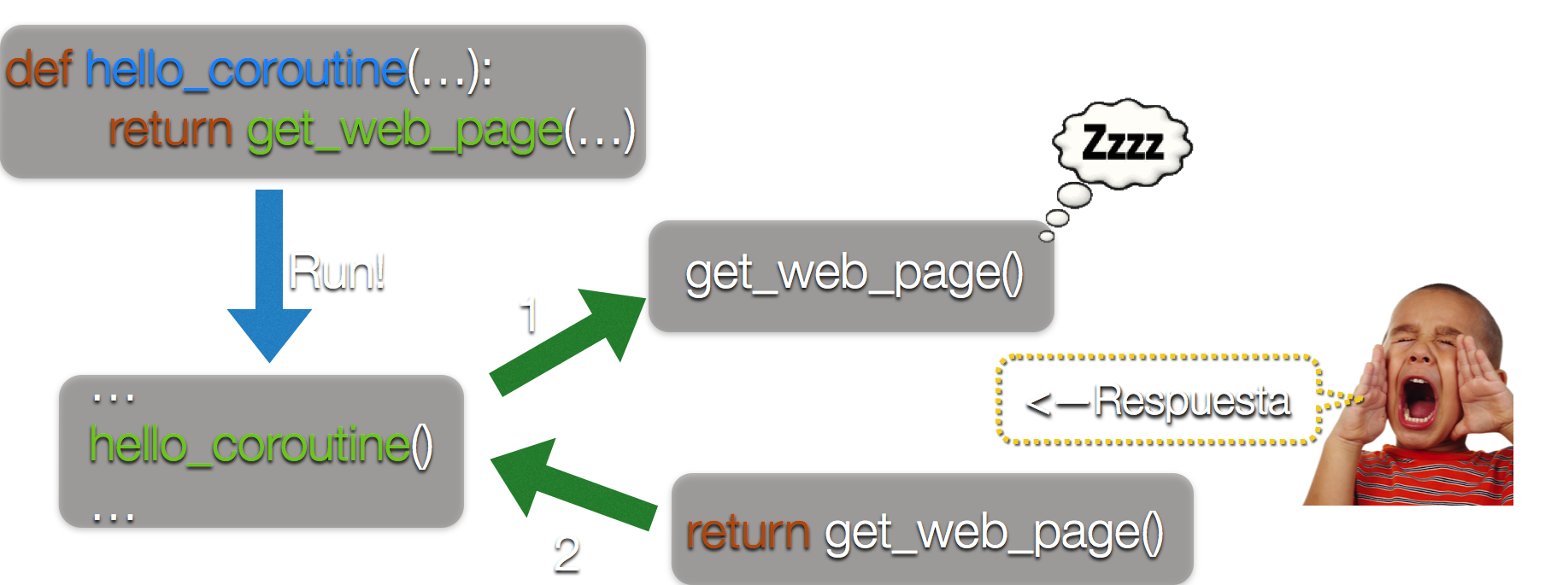
Solución¶
Desde Python 3.4 existen lo que se llaman “corrutinas” a través de la librería, incluida en el framework 3.4, asyncio (también conocido como Tulip).
Cómo¶
Este ejemplo muestra como descargar el contenido de una URL, usando la librería estándar de Python 3.4:
1 2 3 4 5 6 7 8 9 10 11 12 13 | import urllib.request
# ----------------------------------------------------------------------
def main():
req = urllib.request.Request('http://www.navajanegra.com')
response = urllib.request.urlopen(req)
the_page = response.read() # <---- BLOCKING POINT
print(the_page)
if __name__ == '__main__':
main()
|
En el siguiente podemos ver cómo, usando Tulip y la librería aiohttp, podemos hacer peticiones no bloqueantes muy fácilmente:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | import asyncio
import aiohttp
# ----------------------------------------------------------------------
@asyncio.coroutine
def print_page(url):
response = yield from aiohttp.request('GET', url)
body = yield from response.read_and_close(decode=True)
print(body)
# ----------------------------------------------------------------------
def main():
"""Comment"""
loop = asyncio.get_event_loop()
loop.run_until_complete(print_page('http://navajanegra.com'))
if __name__ == '__main__':
main()
|
Nota
aioHTTP es una librería independiente, construida usando asyncIO a bajo nivel, y que nos facilitará el manejo de conexiones HTTP.
LP-002 - Multithreading y procesamiento paralelo¶
Problema¶
Python no tiene hilos ni multithreads real debido al GIL (Global Interpreter Lock). Éste restringe la ejecución a un único hilo corriendo a la vez. Esto es así porque, cuando se diseñó python, se prefirió que el motor fuera más simple su implementación, a costa de sacrificar la eficiente.
Nota
Para entender mejor cómo funciona el GIL, se recomienda al lector las charlas y estudios de David Beazley.
Solución¶
Esto es cierto y no se puede hacer nada a día de hoy. Es el modo de funcionamiento de la VM de Python por defecto, CPython, no se puede lograr, multithreading real.
La solución, para lograr la ejecución pararela en Python, es usar multiprocessing.
Nota
Existen otras implementaciones de la máquina virtual de Python: Diferentes implementaciones de la máquina virtual de PYthon
En el resto de implementaciones SI que existe el mutithread real, pero tienen multitud de incompatibilidades y no es recomendable su uso para propósito general.
Cómo¶
El siguiente código muestra un ejemplo típico de multithreading en Python, en el que solo puede haber 10 threads en ejecución concurrente (que no paralela) a la vez:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | import threading
sem = threading.Semaphore(10)
# ----------------------------------------------------------------------
def hello(i):
print(i)
sem.release()
# ----------------------------------------------------------------------
def main():
threads = []
for x in range(50):
# Create thread
t = threading.Thread(target=hello, args=(x,))
# Start thread
sem.acquire()
t.start()
threads.append(t)
# Wait for end of all threads
map(threading.Thread.join, threads)
if __name__ == '__main__':
main()
|
El siguiente ejemplo muestra el mismo resultado, pero con multiprocessing:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from multiprocessing.pool import Pool
# ----------------------------------------------------------------------
def hello(i):
print(i)
# ----------------------------------------------------------------------
def main():
p = Pool(10)
p.map(hello, range(50))
if __name__ == '__main__':
main()
|
Nota
El código anterior, además de ser multiproceso real, tiene las ventajas:
- Al usar CTRL+C funcionará correctamente.
- Usar una librería del framework, que gestiona internamente, un pool de procesos. Con esto evitamos tener que llevar el control manual del número de procesos concurrentes que pueden ejecutarse.
LP-003 - Callback, número de parámetros y partials¶
Problema¶
Cuando usamos librerías externas o de terceros, tenemos que adaptarnos a su API, pero no siempre es fácil. Supongamos la siguiente situación:
Tenemos una función que ha de invocarse con 3 parámetros a través de un callback externo, pero este callback solo pasa uno de los parámetros requeridos por nuestra función. Con un ejemplo se verá mejor:
Tenemos una librería, llamada external.api, de la que queremos ejecutar una función action_with_callback y cuyo código es:
1 2 3 4 5 6 7 8
def action_with_callback(callback_func=None): from time import sleep from random import randint time_sleep = randint(10, 100) sleep(time_sleep) callback_func(time_sleep)
En nuestro código queremos ejecutar diferentes acciones, en función lo que el usuario indice en la linea de comandos, pero no podemos por el modo de funcionamiento del API externo: No podemos pasar como parámetro la operación y el primer dato:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
from externa.api import action_with_callback def actions(operation, data1, data2): if operation == 0: return data1 / data2 elif operation == 1: return data1 * data2 elif operation == 2: return data1 % data2 if __name__ == "__main__": import sys # Get first and second command line parameters: # arg 0 -> operation # arg 1 -> first value for operation operation = sys.argv[0] data1 = sys.argv[1] action_with_callback(callback_func=actions) # Wrong!!!! -> operation and data1 missing
Solución¶
Usar los partials de Python.
Un partial en una función que se puede construida por partes, dejando una parte fija y otra variable. Siguiendo con el ejemplo anterior:
deberíamos dejar como parte “fija”:
- La operación a realizar
- El primer dato
Y como parte variable, el valor que devuelva el callback.
Es decir, que a partir de la primera función actions(operation, data1, data2), tenemos que generar una segunda con un solo parámetro:
actions(operation, data1, data2) -> TRANSFORM -> new_actions(data2)
Cómo¶
Para construir un partial en Python es muy sencillo, para ello debemos usar la librería functools:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | from functools import partial
from externa.api import action_with_callback
def actions(operation, data1, data2):
if operation == 0:
return data1 / data2
elif operation == 1:
return data1 * data2
elif operation == 2:
return data1 % data2
if __name__ == "__main__":
import sys
# Get first and second command line parameters:
# arg 0 -> operation
# arg 1 -> first value for operation
operation = sys.argv[0]
data1 = sys.argv[1]
new_actions = partial(actions, operation, data1)
action_with_callback(callback_func=new_actions) # Well!
|
LP-004 - “__main__” y ejecuciones accidentales¶
Problema¶
Cuando Python se invoca, por como está concebido, lee y ejecuta todas los los ficheros y dependencias.
Esto puede implicar:
- Llamadas accidentales a métodos, funciones o variables.
- Al no saber el orden exacto de carga de cada fichero, puede provocar errores muy difíciles de detectar.
Por ejemplo:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | class _ListNumbers:
"""Singleton with list numbers"""
def __init__(self):
self.numbers = [x for x in range(100)]
def get_number(self):
return self.numbers[randint(0, len(self.numbers))]
ListNumbers = _ListNumbers()
def hello_word(number):
print("Hello world with number:", number)
hello_word(ListNumbers.get_number())
|
Como podemos ver en el ejemplo, la clase con el listado de números debería de ejecutarse y cargarse antes, pero no podemos estar seguros. Ello depende de la implementación de la máquina virtual de Python.
Es sencillo imaginar por el lector que ocurriría si el orden de carga no fuera el “natural”: Se produciría una condición de carrera y nuestro código fallaría. Las condiciones de carrera son sumamente complicadas de detectar.
Solución¶
Usar la “etiqueta” __name__ para indicar que dicha sección contiene el punto de entrada principal, o función main, a nuestra aplicación.
Cómo¶
En el siguiente código podemos apreciar que el cambio es mínimo. Con este sencillo cambio nos ahorraremos multitud de problemas:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | class _ListNumbers:
"""Singleton with list numbers"""
def __init__(self):
self.numbers = [x for x in range(100)]
def get_number(self):
return self.numbers[randint(0, len(self.numbers))]
ListNumbers = _ListNumbers()
def hello_word(number):
print("Hello world with number:", number)
if __name__ == "__main__":
hello_word(ListNumbers.get_number())
|
LP-005 - Apertura, cierre y olvidos en descriptores¶
Problema¶
Cuando trabajamos con handlers (o descriptores) ya sean de archivo, red o de cualquier otro tipo, sobre ellos hay 3 acciones que siempre llevaremos a cabo:
- Apertura del descriptor.
- Uso del descriptor
- Cierre del descriptor.
El paso 3, cierre del descriptor, es uno de los grandes olvidados por:
- Se omite por descuido del programador.
- No se cierra adecuadamente: a causa de algún problema y errores.
Esto dejará descriptores de sistema abiertos y huérfanos, ocupando recursos del sistema operativo y degradando el rendimiento
El siguiente ejemplo ilustra esta situación:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | from tempfile import TemporaryFile
def main(number):
"""
Generates 100 temporal files with random numbers
"""
for x in range(100):
f = TemporaryFile(mode="w")
f.write(randint(100, 10000))
if __name__ == "__main__":
main()
|
Como se puede ver, en el ejemplo se crean 100 archivos temporales pero no se cierran.
Solución¶
Python dispone de la palabra reservada with que se asegurará de:
- Garantizar una sintaxis sencilla y legible.
- Cerrar el descriptor, y re-intentando o forzando su cierre cuando sea necesario.
with funciona también con sockets, acceso a bases de datos, o cualquier estructura compatible.
Cómo¶
Para usar with tan solo tendremos usar la sintaxis:
1 2 3 | with open("...", ".") as f:
# ACTIONS
f.write("my text")
|
Donde:
- “f” será el descriptor de fichero que usaremos en nuestro código.
- Cualquier acceso que tengamos que hacer sobre el fichero solo podremos hacerlo debajo del bloque del with.
En el momento que la ejecución del bloque finalice, el descriptor se cerrará automáticamente por la VM de Python
Aquí podemos ver el ejemplo anterior usando with:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | from tempfile import TemporaryFile
def main(number):
"""
Generates 100 temporal files with random numbers
"""
for x in range(100):
with TemporaryFile(mode="w") as f:
f.write(randint(100, 10000))
if __name__ == "__main__":
main()
|
LP-006 - import relativos, absolutos, paquetes y demás hierbas¶
Problema¶
Cuando desarrollamos en Python es muy habitual toparnos rápidamentente con mensajes como:
...
ValueError: Attempted relative import in non-package
...
SystemError: Parent module '' not loaded, cannot perform relative import
Estos errores son muy abituales en Python 3.x. Esto es debido a que se está tratando de hacer un import cómo si se tratara de un paquete. Pero... ¿Qué significa esto?
Nota
Python 3.4 introdujo cambios en comportamiento interno cuando importa módulos y dependencias.
Puede leer más sobre este tema consultando el PEP-0366.
Se recomienda la lectura del post de taherh en StackOverFlow: http://stackoverflow.com/a/6655098 , sobre este tema.
Un par de conceptos:
Concepto: Paquete¶
En Python es un proyecto que puede ser importado, para ser usado como librería.
Éstos deberían tener import relativos, para asegurarse que la librería importada es del propio paquete, y no otra del sistema que tenga el mismo nombre.
Podemos ver la importancia de las rutas relativas en el siguiente ejemplo:
Supongamos que nuestra aplicación de ejemplo lp-006-p1.py
1 2 3 | from lp_006_p1.bad import *
lp_006_p1_fn()
|
El ejemplo tiene la estrutura:
1 2 3 4 5 6 7 | lp_006_p1
\__ random
\__ __init__.py
\__ __init__.py
\__ bad.py
\__ good.py
\__ lp-006-p1.py
|
El paquete random tiene el mismo nombre que el incluido en Python, por lo que si escribimos el siguiente código:
1 2 3 4 5 6 | from random import *
# ----------------------------------------------------------------------
def lp_006_p1_fn():
print(HELLO_VAR)
|
Cuantro se trata de mostrar la variable HELLO_VAR, no será encontrada porque realmente estamos importando es el paquete global de Python, y éste no contiene dicha variable. Por tanto se nos mostrará el siguiente error:
Traceback (most recent call last):
File "lp-006-p1.py", line 26, in <module>
lp_006_p1_fn()
File "examples/develop/lp/006/lp_006_p1/bad.py", line 30, in lp_006_p1_fn
print(HELLO_VAR)
NameError: name 'HELLO_VAR' is not defined
Concepto: Aplicación¶
Una definición informa de aplicación de Python es aquella que usa como programa independiente y que tiene como finalidad ser importado por una aplicación externa.
El fichero que contiene el punto de entrada a la aplicación, o main, no puede usar rutas relativas.
¿Por qué sucede esto?
Porque el uso de import relativos solo está permitido para paquetes y han de ser llamados desde paquetes externos, no pueden ser lanzados desde el propio paquete (por defecto).
Es decir, que si tenemos la estructura de directorios usada más arriba, el siguiente código no funcionará:
1 | lp_006_p1_fn()
|
Y nos devolverá el error:
File "lp-006-p2.py", line 24, in <module>
from .lp_006_p1.good import *
SystemError: Parent module '' not loaded, cannot perform relative import
A modo de resumen: No funciona porque se está usando una aplicación como un paquete.
Solución¶
Por su puesto existen soluciones para ambos casos. A modo de conceptual son los siguientes:
Paquetes¶
Usar import relativos, en lugar de absolutos, cuando queramos importar paquetes locales y que éstos no se confundan con los globales u otros que podamos tener instalados.
Aplicación¶
Hay ocasiones en los que querremos usar una aplicación como un paquete como, por ejemplo:
Cuando queramos crear un paquete que, además, pueda ser usado como aplicación.
La solución: forzar la aplicación a que se comporte como un paquete.
Cómo¶
Paquetes¶
La solución es la impotanción relativa o, lo que es lo mismo, indicar a Python que use el paquete local en lugar del global del sistema:
1 2 3 4 5 6 | from .random import *
# ----------------------------------------------------------------------
def lp_006_p1_fn():
print(HELLO_VAR)
|
hello!
Aplicación¶
Transformar una aplicación en un paquete no es nada intuitivo ni trivial. Tendremos que tener controlar:
- Detectar si la aplicación es parte de un paquete o no.
- Mover los import de la parte global al ámbido de la función que haga de punto de entrada. Es ha de ser así para que, cuando el intérprete de Python importe todo el código no ejecute ni cargue ninguna librería hasta que no hayamos transformado la aplicación en paquete.
El siguiente código solucionará nuestro problema:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | # Detect if applitaion is calling out of the box or inside a package.
if __name__ == "__main__" and __package__ is None:
import sys
import os
# Load path of main program file (this file) as a part of path of python interpreter
parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(1, parent_dir)
# Load parent package as a common package
import lp_006_p1
# Set environment package to this package
__package__ = str("lp_006_p1")
del sys, os
# Continue normally
from .lp_006_p1.good import *
lp_006_p1_fn()
|
Explicación line a linea:
- 1: Detectamos si el fichero es el punto de entrada a la aplicación (main) y si es un paquete.
- 7-8: Cargamos el directorio desde el que es llamado el programa en la lista de paquetes disponibles de Python.
- 11: Una vez añadido en el entorno de Python el directorio donde se encuentra nuestro fichero, cargamos el paquete padre, el que contiene el ejecutable, o .py.
- 14: Establecemos la variable de entorno __package__, indicándole a Python que si que existe un paquete.
- 18: Cargamos nuestra librerías con import relativos. Ahora ya no tendremos problemas.
- 20: Continuamos la ejecución de nuestro código, como lo haríamos normalmente.